한줄공지
환영합니다!
로그인
회원가입
한국어
English
日本語
메뉴
홈
BL@G
도구
데이터 변환
JSON 포맷터
Base64
JSON-CSV 변환기
URL 인코더
색상 변환기
타임스탬프 변환기
개발자 도구
정규식 테스터
Diff 비교기
JWT 디코더
UUID 생성기
해시 생성기
메타태그 생성기
마크다운 에디터
이미지 도구
이미지 압축
이미지 변환
무료 AI 이미지 배경 제거
파비콘 생성기
QR코드 생성기
이미지 업스케일
일러스트 파일 변환기
SVG 변환기
웹사이트 목업 생성기
텍스트 & 생활
텍스트 카운터
비밀번호 생성기
날짜 계산기
SEO & 마케팅
키워드 밀도 분석기
robots.txt 생성기
사이트맵 생성기
구조화 데이터 생성기
Open Graph 미리보기
도메인 & IP
도메인 정보 조회
도메인 검색
IP 정보
SSL 인증서 확인
웹사이트 속도 테스트
게임
테트리스
클로드 코드 치트 시트
비트코인
대시보드
반감기 카운트다운
멤풀 현황
해시레이트 & 난이도
라이트닝 네트워크
가격 차트
주소 조회
로그인
회원가입
한국어
English
日本語
BL@G
도구
데이터 변환
JSON 포맷터
Base64
JSON-CSV 변환기
URL 인코더
색상 변환기
타임스탬프 변환기
개발자 도구
정규식 테스터
Diff 비교기
JWT 디코더
UUID 생성기
해시 생성기
메타태그 생성기
마크다운 에디터
이미지 도구
이미지 압축
이미지 변환
무료 AI 이미지 배경 제거
파비콘 생성기
QR코드 생성기
이미지 업스케일
일러스트 파일 변환기
SVG 변환기
웹사이트 목업 생성기
텍스트 & 생활
텍스트 카운터
비밀번호 생성기
날짜 계산기
SEO & 마케팅
키워드 밀도 분석기
robots.txt 생성기
사이트맵 생성기
구조화 데이터 생성기
Open Graph 미리보기
도메인 & IP
도메인 정보 조회
도메인 검색
IP 정보
SSL 인증서 확인
웹사이트 속도 테스트
게임
테트리스
클로드 코드 치트 시트
비트코인
대시보드
반감기 카운트다운
멤풀 현황
해시레이트 & 난이도
라이트닝 네트워크
가격 차트
주소 조회
트레이딩
테슬라 2026년 2분기 실적, 인도량 최고치에도 영업이익 반토막 난 이유
Haru
2026.7.24
17
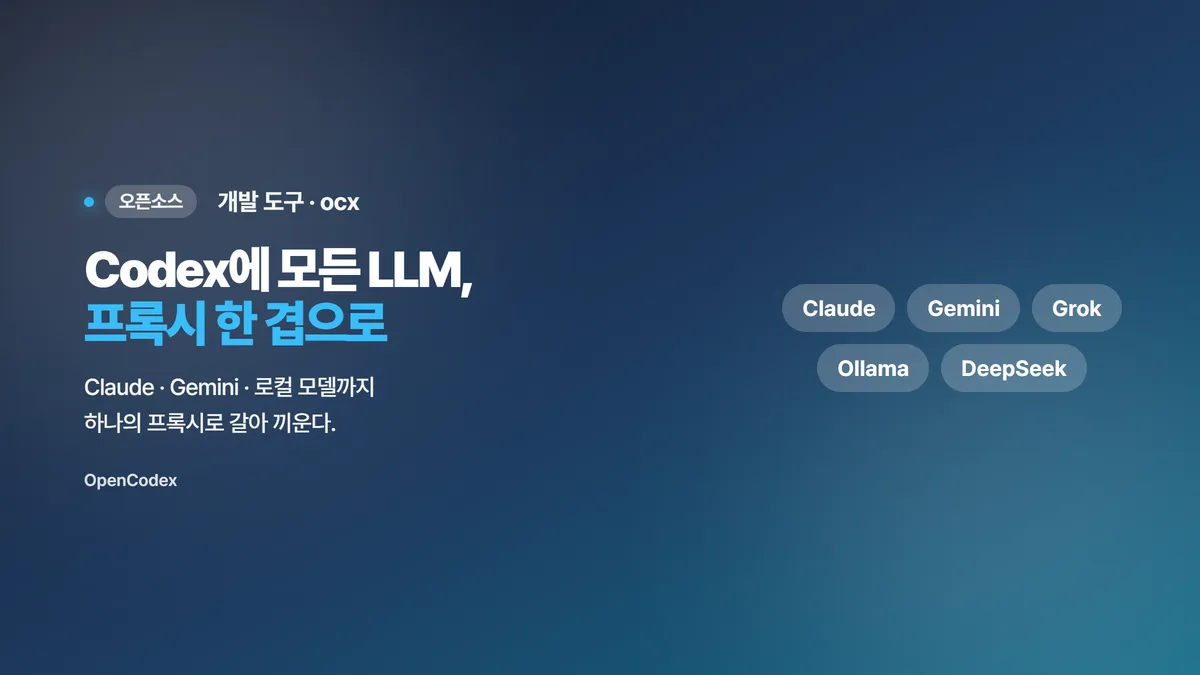
OpenCodex 완벽 정리 — Codex에 Claude·Gemini·로컬 LLM까지 붙이는 유니버설 프록시
2026.7.22
36
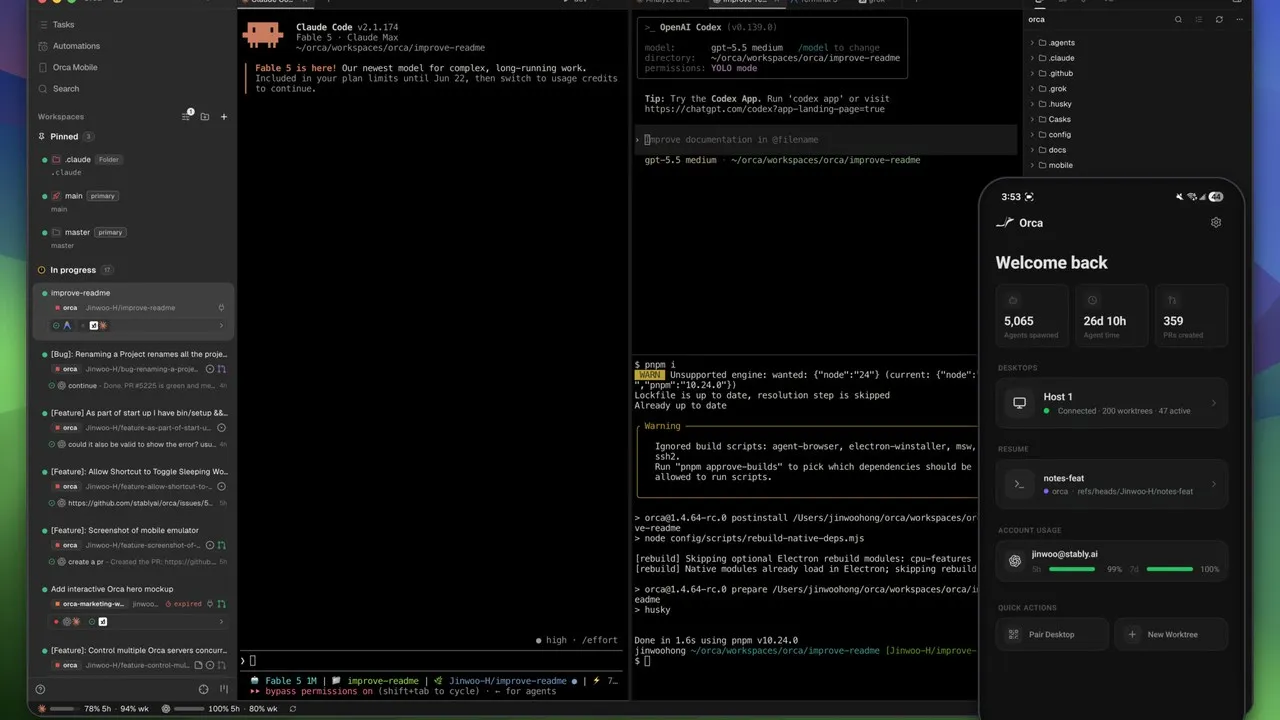
Orca 오픈소스 AI 에이전트 오케스트레이터 병렬 워크트리 실측 리뷰
2026.7.10
52
browseros-ai/BrowserOS AI 에이전트 브라우저 크로미움 포크 실측 리뷰
2026.7.9
199
클로드 Microsoft 365 커넥터, 이제 '쓰기'까지 — 이메일·일정·파일 자동화 총정리
2026.7.8
43
AI
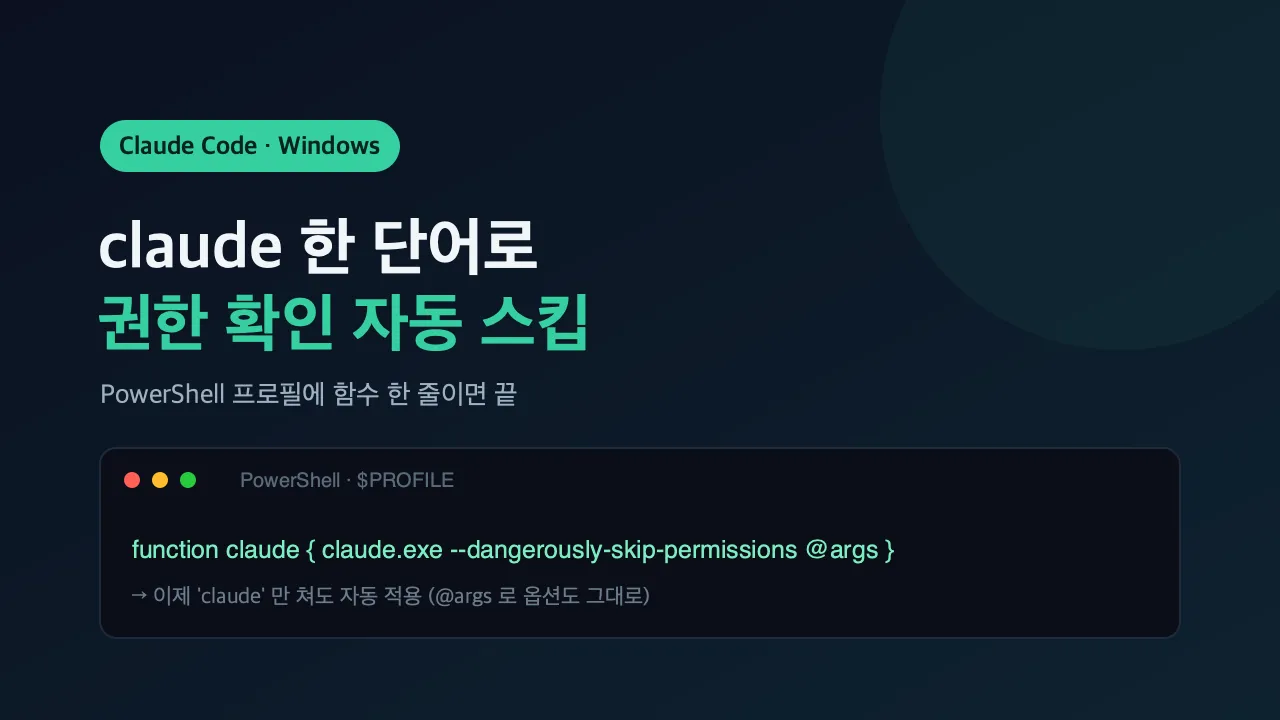
윈도우에서 claude만 쳐도 권한 확인 건너뛰기 (PowerShell 세팅)
2026.6.30
63
프로그래밍
Python
탐지되지 않는 Patchright (Playwright 포크), 설치부터 우회 검증까지
2026.6.25
176
정보
JLPT N5 단어 완벽 정리 — 빈출 어휘 & 플래시카드로 외우는 법 (800단어 한 권)
2026.6.16
51
정보
2026년 여름 휴가 해외여행 동남아 추천 휴양지 BEST 5
2026.6.16
56
인기 게시물
1
browseros-ai/BrowserOS AI 에이전트 브라우저 크로미움 포크 실측 리뷰
2026.7.9
199
2
Orca 오픈소스 AI 에이전트 오케스트레이터 병렬 워크트리 실측 리뷰
2026.7.10
52
3
클로드 Microsoft 365 커넥터, 이제 '쓰기'까지 — 이메일·일정·파일 자동화 총정리
2026.7.8
43
4
OpenCodex 완벽 정리 — Codex에 Claude·Gemini·로컬 LLM까지 붙이는 유니버설 프록시
2026.7.22
36
5
테슬라 2026년 2분기 실적, 인도량 최고치에도 영업이익 반토막 난 이유
2026.7.24
17
인기 도구
전체보기 →
JSON 포맷터
Base64
색상 변환기
JSON-CSV 변환기
URL 인코더
타임스탬프 변환기
정규식 테스터
Diff 비교기
마크다운 에디터
JWT 디코더
UUID 생성기
해시 생성기
메타태그 생성기
스키마 생성기
이미지 압축
이미지 변환
QR코드 생성기
무료 AI 이미지 배경 제거
AI
AI
OpenCodex 완벽 정리 — Codex에 Claude·Gemini·로컬 LLM까지 붙이는 유니버설 프록시
2026.7.22
36
AI
Orca 오픈소스 AI 에이전트 오케스트레이터 병렬 워크트리 실측 리뷰
2026.7.10
52
AI
browseros-ai/BrowserOS AI 에이전트 브라우저 크로미움 포크 실측 리뷰
2026.7.9
199
AI
클로드 Microsoft 365 커넥터, 이제 '쓰기'까지 — 이메일·일정·파일 자동화 총정리
2026.7.8
43
프로그래밍・서버
프로그래밍
Python
탐지되지 않는 Patchright (Playwright 포크), 설치부터 우회 검증까지
2026.6.25
176
프로그래밍
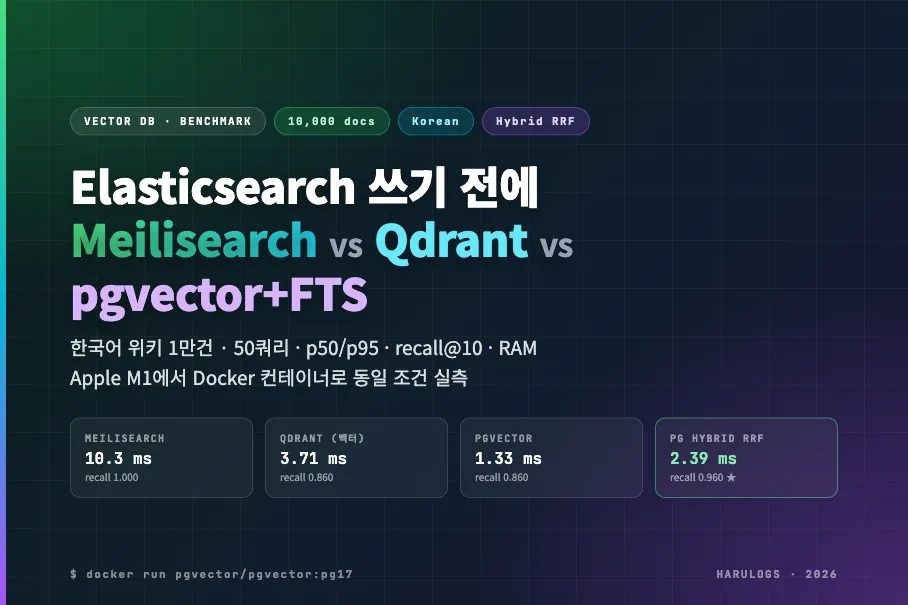
Elasticsearch 쓰기 전에 — Meilisearch vs Qdrant vs pgvector+FTS 하이브리드 1만건 실측
2026.4.30
103
프로그래밍
쿠팡·네이버쇼핑이 막아도 뚫리는 curl-impersonate 완전 가이드 — Python·NodeJS 실측 비교
2026.4.30
106
서버
Ubuntu 26.04에서 MySQL 설치하고 보안까지 끝내는 완전 가이드
2026.4.30
99
트레이딩
트레이딩
테슬라 2026년 2분기 실적, 인도량 최고치에도 영업이익 반토막 난 이유
2026.7.24
17
트레이딩
MetaTrader
메타트레이더4(MetaTrader 4) 다운로드 및 설치 방법
2026.5.12
77
트레이딩
비트코인 반감기 가격 분석: 1~4차 데이터로 보는 5차 반감기 매수 타이밍과 목표 가격
2026.4.8
100
1
트레이딩
MetaTrader
Playground Series EA: FVG와 유동성 기반 MT5 자동매매 시리즈 (v1.00~v1.04)
2026.3.9
236